Publications
(*) denotes equal contribution
2026
- Why is A+B Better Than B? A Simple Graph Perspective on Task Transfer1st Workshop on Foundations of Deep Generative Models (FoGen) at ICML 2026, 2026
Joint training on an auxiliary task A and a target task B routinely outperforms training on B alone, but the conditions and mechanism behind this gap are poorly understood. We ask when, and by how much, an auxiliary task boosts target learning. We model the two tasks as goal-conditioned navigation on a shared directed graph and identify a joint-dominance regime, where neither task alone covers the full target trajectory but their union does. In this regime joint training preserves teacher-level accuracy along the entire target path while single-task training incurs an exponential penalty in the length of its uncovered region. We verify the theory in a controlled GPT-2 study on two algorithmic tasks sharing a depth-first-search backbone, a Qwen2.5 GRPO study on two related math tasks, and a cross-representation procedural-reasoning setting. The findings translate into three checkable criteria for selecting auxiliary tasks: shared sub-skills, joint horizon coverage, and base-policy solvability.
@article{nguyen2026why, title = {Why is A+B Better Than B? A Simple Graph Perspective on Task Transfer}, author = {Nguyen, Dang and Huang, Jianhao and Payani, Ali and Mirzasoleiman, Baharan}, journal = {1st Workshop on Foundations of Deep Generative Models (FoGen) at ICML 2026}, year = {2026} } - Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories3rd Workshop on Navigating and Addressing Data Problems for Foundation Models at ICLR 2026International Conference on Machine Learning (ICML), 2026
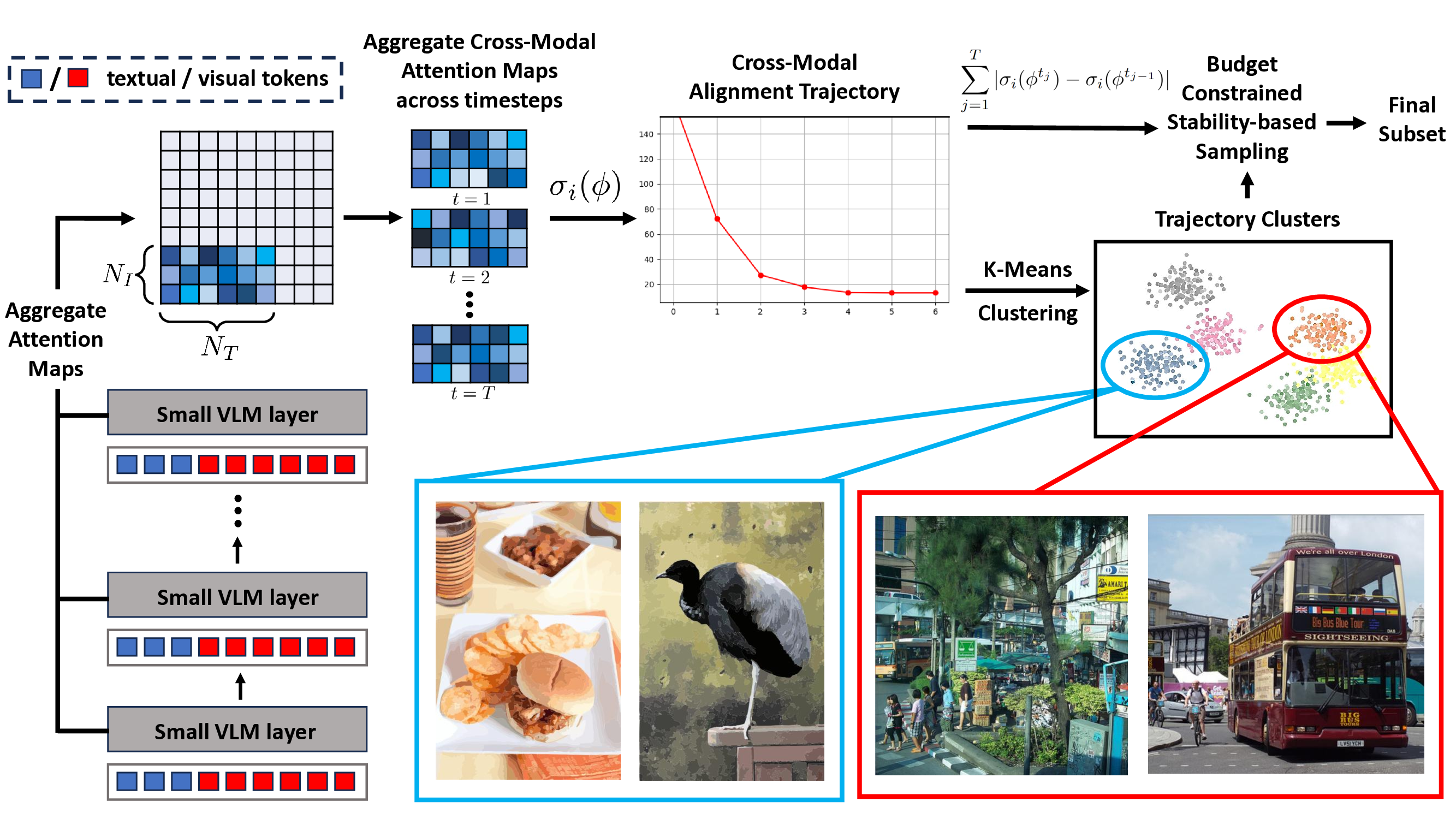
Data-efficient learning aims to eliminate redundancy in large training datasets by training models on smaller subsets of the most informative examples. While data selection has been extensively explored for vision models and large language models (LLMs), it remains underexplored for Large Vision-Language Models (LVLMs). Notably, none of existing methods can outperform random selection at different subset sizes. In this work, we propose the first principled method for data-efficient instruction tuning of LVLMs. We prove that examples with similar cross-modal attention matrices during instruction tuning have similar gradients. Thus, they influence model parameters in a similar manner and convey the same information to the model during training. Building on this insight, we propose XMAS, which clusters examples based on the trajectories of the top singular values of their attention matrices obtained from fine-tuning a small proxy LVLM. By sampling a balanced subset from these clusters, XMAS effectively removes redundancy in large-scale LVLM training data. Extensive experiments across 4 target models, 2 proxy models, and 2 datasets show that XMAS consistently outperforms 10 baseline methods. Moreover, XMAS can discard 50% of the LLaVA-665k dataset and 85% of the Vision-Flan dataset while fully preserving performance of LLaVA-1.5-7B on 10 downstream benchmarks and speeding up its training by 1.2×. This is 30% more data reduction compared to the best baseline for LLaVA-665k. The project’s website can be found at https://bigml-cs-ucla.github.io/XMAS-project-page/
@article{naharas2025data, title = {Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories}, author = {Naharas, Nilay and Nguyen, Dang and Bulut, Neslihan and Bateni, Mohammadhossein and Mirrokni, Vahab and Mirzasoleiman, Baharan}, journal = {International Conference on Machine Learning (ICML)}, year = {2026} } - Do We Need All the Synthetic Data? Towards Targeted Synthetic Image Augmentation via Diffusion ModelsarXiv preprint arXiv:2505.21574, 2026
Synthetically augmenting training datasets with diffusion models has become an effective strategy for improving the generalization of image classifiers. However, existing approaches typically increase dataset size by 10–30× and struggle to ensure generation diversity, leading to substantial computational overhead. In this work, we introduce TADA (TArgeted Diffusion Augmentation), a principled framework that selectively augments examples that are not learned early in training using faithful synthetic images that preserve semantic features while varying noise. We show that augmenting only this targeted subset consistently outperforms augmenting the entire dataset. Through theoretical analysis on a two-layer CNN, we prove that TADA improves generalization by promoting homogeneity in feature learning speed without amplifying noise. Extensive experiments demonstrate that by augmenting only 30–40% of the training data, TADA improves generalization by up to 2.8% across diverse architectures including ResNet, ViT, ConvNeXt, and Swin Transformer on CIFAR-10/100, TinyImageNet, and ImageNet, using optimizers such as SGD and SAM. Notably, TADA combined with SGD outperforms the state-of-the-art optimizer SAM on CIFAR-100 and TinyImageNet. Furthermore, TADA shows promising improvements on object detection benchmarks, demonstrating its applicability beyond image classification. Our code is available at https://github.com/BigML-CS-UCLA/TADA.
@article{nguyen2025we, title = {Do We Need All the Synthetic Data? Towards Targeted Synthetic Image Augmentation via Diffusion Models}, author = {Nguyen, Dang and Li, Jiping and Zheng, Jinghao and Mirzasoleiman, Baharan}, journal = {arXiv preprint arXiv:2505.21574}, year = {2026} }

2025
- Beyond Semantic Entropy: Boosting LLM Uncertainty Quantification with Pairwise Semantic SimilarityDang Nguyen, Ali Payani, and Baharan MirzasoleimanIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
Hallucination in large language models (LLMs) can be detected by assessing the uncertainty of model outputs, typically measured using entropy. Semantic entropy (SE) enhances traditional entropy estimation by quantifying uncertainty at the semantic cluster level. However, as modern LLMs generate longer one-sentence responses, SE becomes less effective because it overlooks two crucial factors: intra-cluster similarity (the spread within a cluster) and inter-cluster similarity (the distance between clusters). To address these limitations, we propose a simple black-box uncertainty quantification method inspired by nearest neighbor estimates of entropy. Our approach can also be easily extended to white-box settings by incorporating token probabilities. Additionally, we provide theoretical results showing that our method generalizes semantic entropy. Extensive empirical results demonstrate its effectiveness compared to semantic entropy across two recent LLMs (Phi3 and Llama3) and three common text generation tasks: question answering, text summarization, and machine translation. Our code is available at https://github.com/BigML-CS-UCLA/SNNE.
@article{nguyen2025beyond, title = {Beyond Semantic Entropy: Boosting LLM Uncertainty Quantification with Pairwise Semantic Similarity}, author = {Nguyen, Dang and Payani, Ali and Mirzasoleiman, Baharan}, journal = {In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)}, year = {2025} } - Synthetic Text Generation for Training Large Language Models via Gradient MatchingInternational Conference on Machine Learning (ICML), 2025
Synthetic data has the potential to improve the performance, training efficiency, and privacy of real training examples. Nevertheless, existing approaches for synthetic text generation are mostly heuristics and cannot generate human-readable text without compromising the privacy of real data or provide performance guarantees for training Large Language Models (LLMs). In this work, we propose the first theoretically rigorous approach for generating synthetic human-readable text that guarantees the convergence and performance of LLMs during fine-tuning on a target task. To do so, we leverage Alternating Direction Method of Multipliers (ADMM) that iteratively optimizes the embeddings of synthetic examples to match the gradient of the target training or validation data, and maps them to a sequence of text tokens with low perplexity. In doing so, the generated synthetic text can guarantee convergence of the model to a close neighborhood of the solution obtained by fine-tuning on real data. Experiments on various classification tasks confirm the effectiveness of our proposed approach. Our code is available at https://github.com/BigML-CS-UCLA/GRADMM.
@article{nguyen2025synthetic, title = {Synthetic Text Generation for Training Large Language Models via Gradient Matching}, author = {Nguyen, Dang and Li, Zeman and Bateni, Mohammadhossein and Mirrokni, Vahab and Razaviyayn, Meisam and Mirzasoleiman, Baharan}, journal = {International Conference on Machine Learning (ICML)}, year = {2025} } - Mini-batch Coresets for Memory-efficient Language Model Training on Data MixturesInternational Conference on Learning Representations (ICLR), 2025
Training with larger mini-batches improves the convergence rate and can yield superior performance. However, training with large mini-batches becomes prohibitive for Large Language Models (LLMs), due to the large GPU memory requirement. To address this problem, an effective approach is finding small mini-batch coresets that closely match the gradient of larger mini-batches. However, this approach becomes infeasible and ineffective for LLMs, due to the highly imbalanced mixture of sources in language data, use of the Adam optimizer, and the very large gradient dimensionality of LLMs. In this work, we address the above challenges by proposing Coresets for Training LLMs (CoLM). First, we show that mini-batch coresets found by gradient matching do not contain representative examples of the small sources w.h.p., and thus including all examples of the small sources in the mini-batch coresets is crucial for optimal performance. Second, we normalize the gradients by their historical exponential to find mini-batch coresets for training with Adam. Finally, we leverage zeroth-order methods to find smooth gradient of the last V-projection matrix and sparsify it to keep the dimensions with the largest normalized gradient magnitude. We apply CoLM to fine-tuning Phi-2, Phi-3, Zephyr, and Llama-3 models with LoRA on MathInstruct and SuperGLUE benchmark. Remarkably, CoLM reduces the memory requirement of fine-tuning by 2x and even outperforms training with 4x larger mini-batches. Moreover, CoLM seamlessly integrates with existing memory-efficient training methods like LoRA, further reducing the memory requirements of training LLMs. Our code is available at https://github.com/BigML-CS-UCLA/CoLM.
@article{nguyen2025mini, title = {Mini-batch Coresets for Memory-efficient Language Model Training on Data Mixtures}, author = {Nguyen, Dang and Yang, Wenhan and Anand, Rathul and Yang, Yu and Mirzasoleiman, Baharan}, journal = {International Conference on Learning Representations (ICLR)}, year = {2025} }
2024
- Changing the Training Data Distribution to Reduce Simplicity Bias Improves In-distribution GeneralizationAdvances in Neural Information Processing Systems, 2024
Can we modify the training data distribution to encourage the underlying optimization method toward finding solutions with superior generalization performance on in-distribution data? In this work, we approach this question for the first time by comparing the inductive bias of gradient descent (GD) with that of sharpness-aware minimization (SAM). By studying a two-layer CNN, we prove that SAM learns easy and difficult features more uniformly, particularly in early epochs. That is, SAM is less susceptible to simplicity bias compared to GD. Based on this observation, we propose USEFUL, an algorithm that clusters examples based on the network output early in training and upsamples examples with no easy features to alleviate the pitfalls of the simplicity bias. We show empirically that modifying the training data distribution in this way effectively improves the generalization performance on the original data distribution when training with (S)GD by mimicking the training dynamics of SAM. Notably, we demonstrate that our method can be combined with SAM and existing data augmentation strategies to achieve, to the best of our knowledge, state-of-the-art performance for training ResNet18 on CIFAR10, STL10, CINIC10, Tiny-ImageNet; ResNet34 on CIFAR100; and VGG19 and DenseNet121 on CIFAR10. Our code is available at https://github.com/BigML-CS-UCLA/TADA.
@article{nguyen2024make, title = {Changing the Training Data Distribution to Reduce Simplicity Bias Improves In-distribution Generalization}, author = {Nguyen, Dang and Haddad, Paymon and Gan, Eric and Mirzasoleiman, Baharan}, journal = {Advances in Neural Information Processing Systems}, year = {2024} } - Understanding the Robustness of Multi-modal Contrastive Learning to Distribution ShiftData-centric Machine Learning Research (DMLR) Workshop at ICLR 2024International Conference on Learning Representations (ICLR), 2024
Recently, multimodal contrastive learning (MMCL) approaches, such as CLIP, have achieved a remarkable success in learning representations that are robust against distribution shift and generalize to new domains. Despite the empirical success, the mechanism behind learning such generalizable representations is not understood. In this work, we rigorously analyze this problem and uncover two mechanisms behind MMCL’s robustness: \emphintra-class contrasting, which allows the model to learn features with a high variance, and \emphinter-class feature sharing, where annotated details in one class help learning other classes better. Both mechanisms prevent spurious features that are over-represented in the training data to overshadow the generalizable core features. This yields superior zero-shot classification accuracy under distribution shift. Furthermore, we theoretically demonstrate the benefits of using rich captions on robustness and explore the effect of annotating different types of details in the captions. We validate our theoretical findings through experiments, including a well-designed synthetic experiment and an experiment involving training CLIP on MS COCO and evaluating the model on variations of shifted ImageNet.
@article{xue2024robustness, title = {Understanding the Robustness of Multi-modal Contrastive Learning to Distribution Shift}, author = {Xue, Yihao and Joshi, Siddharth and Nguyen, Dang and Mirzasoleiman, Baharan}, journal = {International Conference on Learning Representations (ICLR)}, year = {2024}, }
2023
- Self-Attention Amortized Distributional Projection Optimization for Sliced Wasserstein Point-Cloud ReconstructionKhai Nguyen*, Dang Nguyen*, and Nhat HoInternational Conference on Machine Learning (ICML), 2023
Max sliced Wasserstein (Max-SW) distance has been widely known as a solution for less discriminative projections of sliced Wasserstein (SW) distance. In applications that have various independent pairs of probability measures, amortized projection optimization is utilized to predict the “max" projecting directions given two input measures instead of using projected gradient ascent multiple times. Despite being efficient, Max-SW and its amortized version cannot guarantee metricity property due to the sub-optimality of the projected gradient ascent and the amortization gap. Therefore, we propose to replace Max-SW with distributional sliced Wasserstein distance with von Mises-Fisher (vMF) projecting distribution (v-DSW). Since v-DSW is a metric with any non-degenerate vMF distribution, its amortized version can guarantee the metricity when performing amortization. Furthermore, current amortized models are not permutation invariant and symmetric. To address the issue, we design amortized models based on self-attention architecture. In particular, we adopt efficient self-attention architectures to make the computation linear in the number of supports. With the two improvements, we derive self-attention amortized distributional projection optimization and show its appealing performance in point-cloud reconstruction and its downstream applications
@article{nguyen23self, title = {Self-Attention Amortized Distributional Projection Optimization for Sliced {W}asserstein Point-Cloud Reconstruction}, author = {Nguyen, Khai and Nguyen, Dang and Ho, Nhat}, journal = {International Conference on Machine Learning (ICML)}, year = {2023}, url = {https://proceedings.mlr.press/v202/nguyen23e.html}, } - On Cross-Layer Alignment for Model Fusion of Heterogeneous Neural NetworksTop 3%IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023
Layer-wise model fusion via optimal transport, named OTFusion, applies soft neuron association for unifying different pre-trained networks to save computational resources. While enjoying its success, OTFusion requires the input networks to have the same number of layers. To address this issue, we propose a novel model fusion framework, named CLAFusion, to fuse neural networks with a different number of layers, which we refer to as heterogeneous neural networks, via cross-layer alignment. The cross-layer alignment problem, which is an unbalanced assignment problem, can be solved efficiently using dynamic programming. Based on the cross-layer alignment, our framework balances the number of layers of neural networks before applying layer-wise model fusion. Our experiments indicate that CLAFusion, with an extra finetuning process, improves the accuracy of residual networks on the CIFAR10, CIFAR100, and Tiny-ImageNet datasets. Furthermore, we explore its practical usage for model compression and knowledge distillation when applying to the teacher-student setting.
@article{nguyen2021model, title = {On Cross-Layer Alignment for Model Fusion of Heterogeneous Neural Networks}, author = {Nguyen, Dang and Nguyen, Trang and Nguyen, Khai and Phung, Dinh and Bui, Hung and Ho, Nhat}, journal = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, year = {2023}, published = {true}, }

2022
- Improving Mini-batch Optimal Transport via Partial TransportationInternational Conference on Machine Learning (ICML), 2022
Mini-batch optimal transport (m-OT) has been widely used recently to deal with the memory issue of OT in large-scale applications. Despite their practicality, m-OT suffers from misspecified mappings, namely, mappings that are optimal on the mini-batch level but are partially wrong in the comparison with the optimal transportation plan between the original measures. Motivated by the misspecified mappings issue, we propose a novel mini-batch method by using partial optimal transport (POT) between mini-batch empirical measures, which we refer to as mini-batch partial optimal transport (m-POT). Leveraging the insight from the partial transportation, we explain the source of misspecified mappings from the m-OT and motivate why limiting the amount of transported masses among mini-batches via POT can alleviate the incorrect mappings. Finally, we carry out extensive experiments on various applications such as deep domain adaptation, partial domain adaptation, deep generative model, color transfer, and gradient flow to demonstrate the favorable performance of m-POT compared to current mini-batch methods.
@article{nguyen22improving, title = {Improving Mini-batch Optimal Transport via Partial Transportation}, author = {Nguyen, Khai and Nguyen, Dang and Vu-Le, The-Anh and Pham, Tung and Ho, Nhat}, journal = {International Conference on Machine Learning (ICML)}, year = {2022}, url = {https://proceedings.mlr.press/v162/nguyen22e.html}, } - On Transportation of Mini-batches: A Hierarchical ApproachInternational Conference on Machine Learning (ICML), 2022
Mini-batch optimal transport (m-OT) has been successfully used in practical applications that involve probability measures with a very high number of supports. The m-OT solves several smaller optimal transport problems and then returns the average of their costs and transportation plans. Despite its scalability advantage, the m-OT does not consider the relationship between mini-batches which leads to undesirable estimation. Moreover, the m-OT does not approximate a proper metric between probability measures since the identity property is not satisfied. To address these problems, we propose a novel mini-batch scheme for optimal transport, named Batch of Mini-batches Optimal Transport (BoMb-OT), that finds the optimal coupling between mini-batches and it can be seen as an approximation to a well-defined distance on the space of probability measures. Furthermore, we show that the m-OT is a limit of the entropic regularized version of the BoMb-OT when the regularized parameter goes to infinity. Finally, we carry out experiments on various applications including deep generative models, deep domain adaptation, approximate Bayesian computation, color transfer, and gradient flow to show that the BoMb-OT can be widely applied and performs well in various applications.
@article{nguyen2021transportation, title = {On Transportation of Mini-batches: A Hierarchical Approach}, author = {Nguyen, Khai and Nguyen, Dang and Nguyen, Quoc and Pham, Tung and Bui, Hung and Phung, Dinh and Le, Trung and Ho, Nhat}, journal = {International Conference on Machine Learning (ICML)}, year = {2022}, url = {https://proceedings.mlr.press/v162/nguyen22d.html}, }